LLM 学习笔记
1. 语言模型
语言模型,从我个人的理解,是可以理解并生成文本的模型。
理解文本的第一步是理解单词,语言模型使用词向量来表示单词,词向量是一个拥有多维度的数字向量。我们很容易就会想到一个词的含义不是固定的,在不同的语境下它可能表示不同的意思,因此词向量也要结合上下文的语义。这里就需要用到知名的 Transformer 结构了。
(这里的词其实指的是 token。)
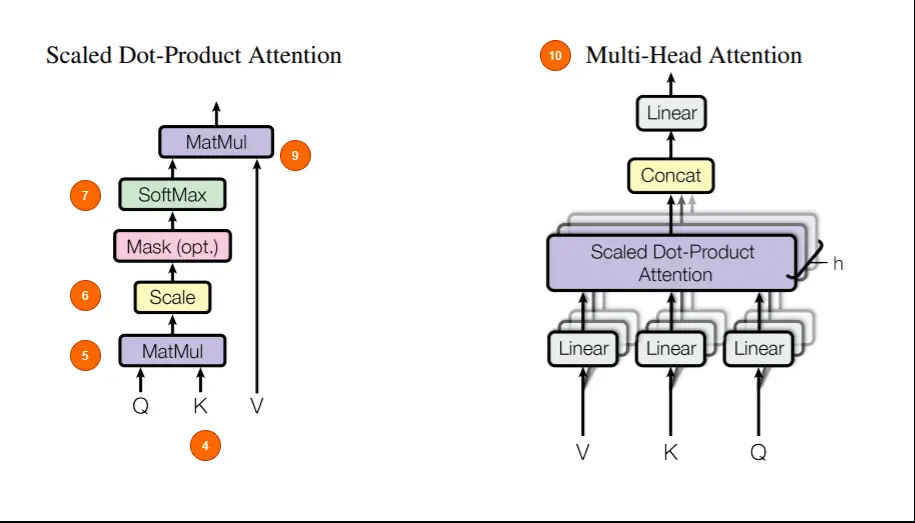
模型会修改词向量来储存信息,这中间信息对于人类来说难以理解,被称为 hidden state。Transformer 在更新输入段落的每个单词的隐藏状态时有两个处理过程:
- 注意力机制中,每个词收集上下文,并与最相关的词分享信息
- 前馈步骤中,汇总信息,并预测下一个单词
注意力机制可以看做是一次配对,每个词向量都有自己的值(key),和自己想要的值(query),每个词用自己想要的 query 去和别人的 key 比较,并把自己的值(value)与其结合。
多头注意力中每个注意力都会关注到不同的任务,最后将得到的信息汇总,送入下一层。
由此可见词向量里要存的信息不只是一个词自己的含义,还有一些上下文相关的信息,可能就像:“John(人名,男性,汽车司机,拿着车钥匙)”,从而预测出 John 要去开车的信息。
GPT-3 最大的版本的词向量有 12288,其中所包含的信息也许比我上面胡扯的这段还要多。
前馈网络拥有大量神经元连接,在GPT-3中FFN的参数量占了近三分之二。FFN 可以视为储存训练数据中信息的数据库。
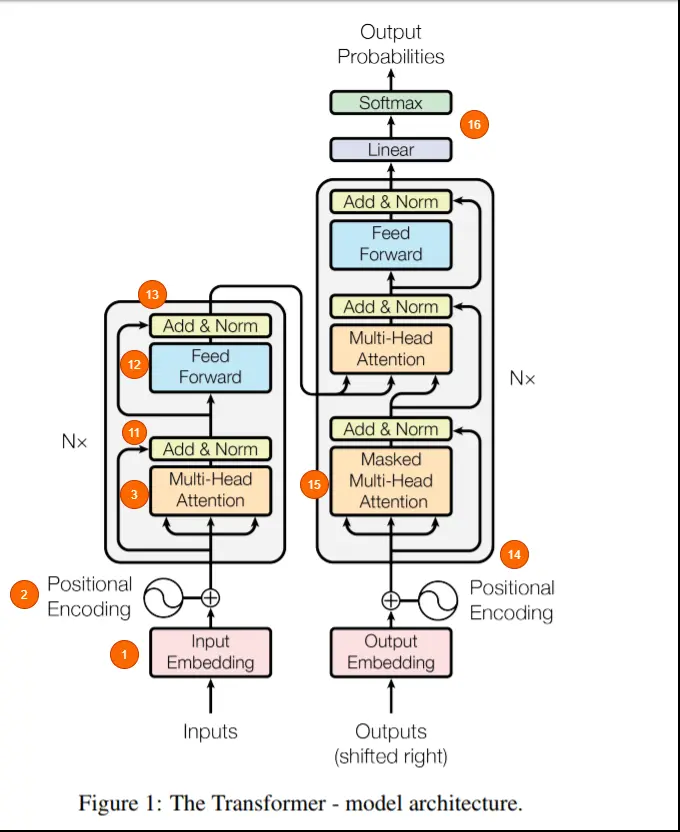 Transformer 结构
Transformer 结构
2. 架构
Transformer 架构中的编码器部分负责理解和提取输入文本中的相关信息,它 输出的是输入文本的一个连续表示(嵌入),然后将其传递给解码器。最终,解码器根据从编码器接收到的连续表示生成翻译后的文本(目标语言)。
Encoder-only 的构架包括 BERT 和 RoBERTa,该类语言模型擅长文本理解,因为它们允许信息在文本的两个方向上流动。双向的能力来自 transformer encoder 中每个词对其他所有词的注意力。
BERT 在两个不同但相关的 NLP 任务上进行了预训练: 屏蔽语言模型和下一句预测。
屏蔽语言模型 (Masked Language Model,MLM) 训练的目的是在句子中隐藏一个单词,用 [MASK] 代替,然后让模型根据隐藏单词的上下文预测被隐藏(masked)的单词。
下一句预测训练(Next Sentence Prediction,NSP)的目的是让模型预测给定的两个句子是否有逻辑上的顺序联系,或者它们之间的关系是否只是随机的。两个句子用 [SEP] 隔开。
RoBERTa(Robustly optimized BERT approach)是 BERT 的优化版本,更好地处理各种自然语言理解任务。
Decoder-only 的模型中信息只能从左到右,擅长文本生成。GPT 系列都是 decoder-only 的结构。
自回归特效让模型以先前生成的词作为上下文,生成下一个词。
encoder-decoder 构架,理论上结合了上面两种模型,能理解并生成文本,包括 BART 和 T5。
Encoder-only 实际上也有 decoder,只不过不像其他两种结构可以直接输出文本,而是可以完成特定的任务,比如根据输入文本进行标签预测。
3. 预训练和微调
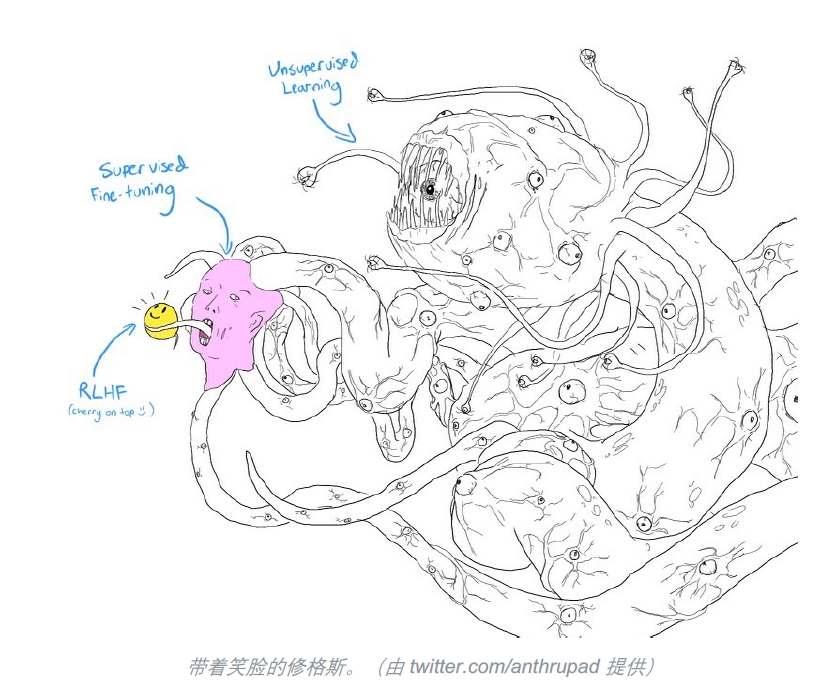
预训练是从头训练一个 LLM 的第一步。从大量低质量的无标注文本数据中,用 BERT 的方式训练模型完形填空,或者用 GPT 的方式训练模型预测下一个 token。
预训练出来的模型可以拿来直接用,但是你会发现它的表现可能和你的预期并不一致。这时就需要监督微调(Supervised Finetune,SFT)。
在 SFT 阶段,模型从演示数据中学习,演示数据一般遵循着(提示, 回答)对的方式,由高质量人类生成(标注团队约90%至少拥有学士学位,超过三分之一拥有硕士学位————InstructGPT)。
InstructGPT 证明在 SFT+RLHF 比只是用 SFT 效果更好。SFT 会告诉模型如何回答问题,却不会告诉模型回答的好不好。
使用 RLHF 首先需要训练一个奖励模型进行评分, 然后微调 LLM 以获得高分回答。奖励模型(RM)的任务是为一对(提示,回答)输出分数,只有排名会被用于训练 RM。在使用 RM 进行微调时, Proximal Policy Optimization(PPO)是一个常用的方法,会从一个分布中随机选择提示,每个提示被依次输入至LLM模型中,得到一个回答,并通过 RM 给予回答一个相应评分。
4. 幻觉
幻觉指的是模型一本正经的胡说八道的现象,一种说法时幻觉来自 LLM 对因果关系缺乏理解,另一种说法是 LLM 的内部知识与人类内部知识不匹配。
向量嵌入(vector embeddings)似乎是一个很好的解决方案,它为 LLM 创建一个长期记忆的数据库,提供可靠的信息。与传统的数据库不同,向量数据库储存的是一种数值形式的模型内部表达。