论文笔记-nnUNet Revisited-呼吁对 3D 医学图像分割进行严格验证
nnUNet revisited 论文: nnU-Net Revisited: A Call for Rigorous Validation in 3D Medical Image Segmentation
nnUNet 论文:nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation
nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation
更新文档:https://github.com/MIC-DKFZ/nnUNet
nnUNet 笔记:https://bigfishtwo.github.io/posts/nnUNet/
太长不看版
更新了 nnUNetPlannerResEnc(M/L/XL) 三种预设,适配中杯(9-11GB VRAM)、大杯(24GB VRAM)和超大杯(40GB VARM)的 GPU 配置,推荐使用 ‘nnU-Net ResEnc L’ 作为新的默认配置。
新配置兼容 2d 和 3d_fullres 配置相同的预处理数据文件夹, 3d_lowres 不同。 预处理:
1
nnUNetv2_plan_and_preprocess -d DATASET -pl nnUNetPlannerResEncL
生成 plan:
1
nnUNetv2_plan_experiment -d DATASET -pl nnUNetPlannerResEncL
训练:
1
nnUNetv2_train -d DATASET -p nnUNetResEncUNetLPlans
1. 前情提要
nnUNet 自打 2018 年提出来就一直是医学图像分割领域的一座不可撼动的大山,这些年来计算机视觉领域出现了各种花式的创新,比如已经占据主流地位的 Transformer 和新出现的 Mamba,虽然每一篇使用了创新架构的文章,都用 nnUNet 做 baseline,并且声称性能超过了使用”过时“CNN架构的 nnUNet,但是在实际使用时不难发现,只要换一个数据集这些新架构就会变差。
nnUNet 的作者团队也注意到了这点,于是写了这篇文章激情开麦,揭露了在医学图像分割中的一些常见的验(水)证(论)不(文)足(的)问(方)题(法)。
2. 验证陷阱
2.1 与基线相关的陷阱
P1:将所声称的创新与令人困惑的性能增强器结合起来:
一个例子是在创新的 encoder 里使用了 残差连接,而 baseline encoder 只使用 vanilla CNN。被引用(点名批评)的是 U-mamba(2024) 😂。
另一个例子是将所声称的创新与基线中未使用的额外训练数据相结合,点名 Unetr(2022)。
一个相关的陷阱是将所声称的创新与自我监督预训练结合起来,而基线则从头开始训练(Swin UNETR,2022) 🤐。
第三个例子是将所声称的创新与更大的硬件功能相结合,即与未缩放到相同计算预算的基线进行比较(Mednext,2023)。
最后,有的仅基于排行榜结果宣传自己创新,但是使用了 20折的ensemble,而排行榜上其他人没有使用如此昂贵的性能助推器。
建议(R1):确保所提出的方法没有与性能提高因素混在一起,与 baseline 进行公平比较,确保验证是有意义的。
P2:缺乏配置良好和标准化的基线:
nnU-Net 已经证明,正确的方法配置通常比架构本身对性能的影响更显着。这表明,如果基于与配置不当的基线(即具有不透明且可能低于标准的超参数优化的手动配置的 U-Net)进行比较,则可能会产生误导(点名一堆论文)。
建议(R2):除了要求确保基线的高质量配置之外,只有新提出的方法提供了适应性说明,或能在自动配置框架中以复现其能力,才能实现该领域的长期标准化。
2.2 与数据集有关的陷阱
P3:数据集的数量和适用性不足:
nnU-Net 研究包含的实验证明了:
1) 生物医学数据集的巨大多样性和
2) 在声称一般方法论进步时,需要对足够数量和种类的数据集进行测试
然而,最近研究中声称具有优异分割性能的数据集的中位数为三个,其中一部分基准由 BTCV 或 BraTS 组成,这里的两个数据集在后面的实验里被作者认定为不适合评估一般方法。
建议(R3):使用合适的数据集来验证方法,包括足够的数据集数量和多样性,以及单个数据集的基准测试适用性。
P4:不一致的报告实践:
公开排行榜提交的标准化是有限的,例如允许不同的集成策略、测试时间增强和后处理技术。这种非标准化的设置,虽然可以证明所提出的方法,但削弱了得出有意义的方法论结论的能力。因此,研究人员经常通常会采用自定义的训练/测试分割方法,以对照基线进行控制比较,但这些方法通常涉及较小的测试集,会带来次大的结果不稳定性,并质疑微小性能提升的意义。此外,在没有正当理由的情况下,只对数据集中的特定类别报告选择性结果的做法,也进一步损害了结果的完整性。
建议 (R4):区分开发数据集库和独立的测试数据集库,以对照基线进行交叉验证,可对方法性能进行更可靠的评估。
3. 系统的 3D 医疗分割基准
3.1 比较方法
基于 CNN:使用 vanilla U-Ne 包含 nnU-Net 的原始配置以及在编码器中采用带有残差连接的 U-Net 的变体(“nnU-Net ResEnc”),该变体自 2019 年以来已成为官方存储库的一部分
本着避免未来对不平等硬件设置进行基准测试的精神(参见 P1),作者引入了新的 nnU-Net ResEnc 预设,它使用自动适应 batch 和 patch 大小来针对不同的 VRAM 预算(“M”、 “L”、“XL”)。
作者还包括了 MedNeXt 和 STU-Net。
基于 Transformer:作者测试了 SwinUNETR 的原始版本, 以及 version 2 、nnFormer 和 CoTr。
基于 Mamba:作者测试最近提出的 U-Mamba 模型,在 U-Net 编码器(“U-Mamba Enc”)或专门在瓶颈(“U-Mamba Bot”)中使用 Mamba 层。作者还使用相同的设置,同时关闭曼巴层(“No-Mamba Base”),添加了原始出版物中缺失的消融。
除了SwinUNETR(V1+V2)之外,上述所有方法最初都是在nnU-Net框架中实现的。
框架比较:除了比较最近的方法,作者还将 nnU-Net 与最近的替代框架进行了基准比较: Auto3DSeg(Version 1.3.0)是 MONAI 生态系统的一部分,赢得了 KiTS2023 等多项挑战,在 MICCAI 2023 上引起了轰动,从而将自己定位为 nnU-Net 的替代品,并承诺提供相同的自动配置功能。作者对该框架通过三种特色架构(“SegResNet”、“DiNTS”、“SwinUNETR”进行了测试.
本着 R1 和 R2 的精神,作者采用标准化方案进行超参数配置,方法是:
1) 使用方法的自配置能力(如果可用),
2) 如果提供了多个配置,则选择最接近各自数据集的配置,
3) 在没有提供替代方案的情况下使用默认配置,或
4) 在必要时降低学习率直到实现收敛。所有模型都是从头开始训练的。唯一的例外是 Auto3DSeg 框架中的 SwinUNETR。
作者还通过在具有 40GB VRAM 的单个 NVIDIA A100 上运行所有训练,在所有方法中采用相同的最大 VRAM 预算。此预算不包括作者的基准中最大的 STU-Net 变体(“H”)。
3.2 使用的数据集
作者的基准测试使用了六个数据集:BTCV、ACDC、LiTS、 BraTS2021 、KiTS2023 和 AMOS2022。作者根据流行度选择数据集,使作者能够遵循 R3 并评估流行的数据集及其对方法基准测试的适用性。
为了确保基准数据集能够测量出一致的方法学差异信号,作者得出了两个适用性要求:
1)五种折叠方法中同一方法的 DSC 分数的标准偏差(SD)较低(方法内 SD),这表明统计稳定性和信噪比较高。
2)不同方法之间的标准偏差(方法间 SD)高,表明方法差异的信号有意义,即在各自任务上的性能不会过快饱和。作者最终的适合度得分是方法间差异与方法内差异的比率。
在 R4 之后,作者使用 5 倍交叉验证来报告结果,采用 nnU-Net 生成的分割,并在所有方法中一致地应用这些结果。由于作者在本研究中没有开发新方法,因此作者不区分开发数据集池和测试数据集池。作者报告结果时,平均 Dice 相似系数(DSC)是作者的主要指标,归一化表面距离(NSD)是作者的次要指标。对于这两个指标,结果对每个数据集的所有类别以及五倍进行平均,以评估通才分割能力,而无需深入研究特定问题的指标细微差别。对于具有分层评估区域(BraTS2021、KiTS2023)的数据集,作者计算这些区域而不是非重叠类的指标。
4. 结果与讨论
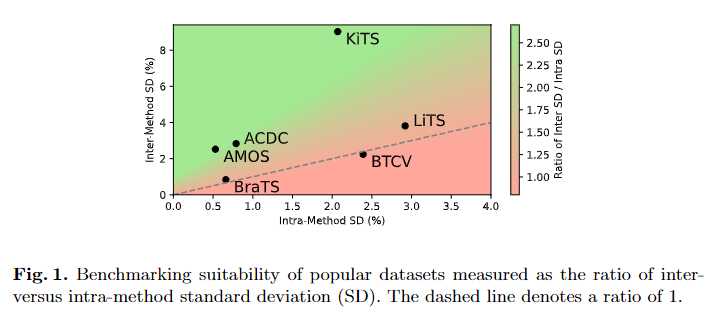
图 1 显示了基于作者的基准的数据集分析结果。
KiTS、AMOS 和 ACDC 是最适合对 3D 分割方法进行基准测试的数据集。 作者发现 KiTS、AMOS 和 ACDC 表现出低统计噪声(方法内 SD),同时有效区分方法,如高方法间 SD 所示。在这三者中,KiTS 具有迄今为止最高的方法间 SD,表明该任务的性能饱和度最低。相反,BraTS21 上的分数已经饱和,方法之间和内部的差异最小。BTCV 的 SD 比率低于 1,表明统计噪声可能超过方法之间性能差异的信号。 LiTS 代表了基准测试适用性的中间立场。总之,ACDC、AMOS 和 KiTS 可以被推荐为最适合基准测试的数据集,BraTS、LiTS 和 BTCV 被认为不太适合此目的。
[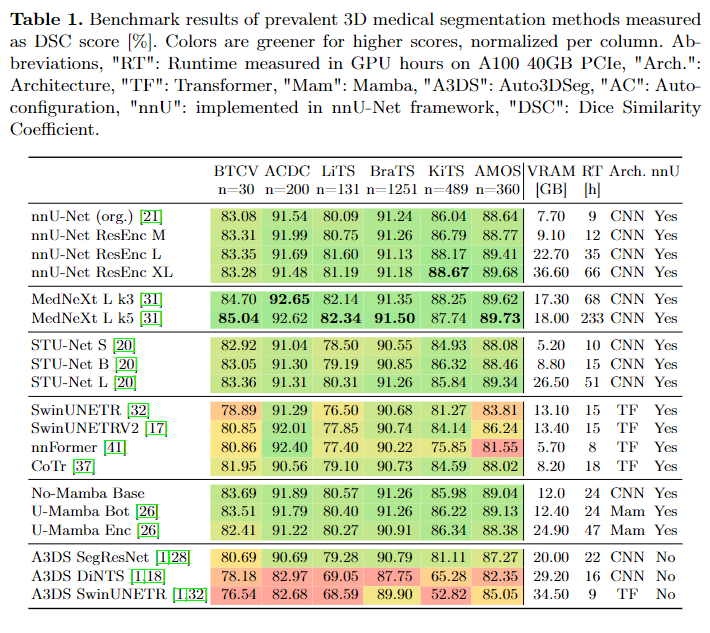
基于 CNN 的 U-Net 具有最佳性能。 在 nnU-Net 中实现的基于 CNN 的 U-Net 在所有六个数据集上始终提供强大的性能。除了原始的 nnU-Net 之外,还包括 STUNet、Res-Enc M/L/XL、MedNeXt 和 No-Mamba base。 MedNeXt 在除 KITS 之外的所有数据集上始终以最佳性能脱颖而出,尽管在基准测试适用性较高的数据集上差距较小。此外,MedNeXt 的性能提升是以增加训练时间(尤其是 k5)为代价的。附录表 5 中的其他实验表明,MedNeXt 的部分优势可以通过目标间距选择来解释,因此并不完全与卓越的架构相关。
与之前的说法相反,基于 Transformer 的架构(SwinUNETR、nn-Former、CoTr)无法与 CNN 的性能相匹配。这包括与原始 nnU-Net 的性能不匹配,该网络早在基于 Transformer 的架构之前就已发布。 CoTr 显示了 Transformer 类别中的最佳结果,先前的文献与其卷积组件相关。 U-Mamba 最初似乎在分割任务中表现良好,但与之前缺失的基线“No-Mamba Base”进行比较表明,mamba 层实际上对性能没有影响,相反,最初报告的增益是由于耦合了该方法带有残差 U-Net。 SegResNet 在 Auto3DSeg 中实现的方法中表现出最佳性能,这一事实强调了观察到的 CNN 的优越性不仅仅是 nnU-Net 引入的偏差。
nnU-Net 是最先进的分割框架。作者发现 Auto3DSeg 中的三种方法都没有达到原始 nnU-Net 基线(“org.”)性能,这表明由于底层 Auto3DSeg 框架而存在很大的劣势。尽管 nnU-Net 基线的 VRAM 使用率和训练时间显着降低,但还是出现了这种负差距。当使用相同的方法 (SwinUNETR) 比较两个框架时,nnU-Net 在 6 个数据集中赢得了 5 个。按照官方 Auto3DSeg 教程 [2],作者通过手动更改配置并进一步增加其计算预算来改进结果,但未能达到有竞争力的性能(参见附录表 2)。总而言之,虽然 Auto3DSeg 可以被推动产生最先进的结果,正如它最近赢得的挑战所证明的那样,但它的开箱即用功能与 nnU-Net 不匹配。
缩放模型很重要,特别是在较大的数据集上,作者基于两种方法测试了模型缩放的效果:nnU-Net Resenc M/L/XL 和 STU-Net S/B/L。作者发现,在更具挑战性的任务 AMOS 和 KiTS 上,随着计算预算的增加,性能显着提升。正如预期的那样,“更简单”的任务 BTCV 和 BraTS 从模型扩展中获得性能提升的潜力较小。这些发现强调了大小意识和数据集意识对于有意义的方法比较的重要性。例如,大型新分割模型的优越性的证据不应该基于与小得多的原始 nnU-Net 的比较。
5. 结论
作者的基准揭示了 3D 医学图像分割的一个令人担忧的趋势:近年来引入的大多数方法都未能超越 2018 年引入的原始 nnU-Net 基线。这就提出了一个问题:作者如何引导该领域取得真正的进步?在这项研究中,作者将观察到的缺陷与方法验证普遍缺乏严格性联系起来。为了解决这个问题,作者引入:
1)系统收集验证陷阱以及避免这些陷阱的建议,
2)发布更新的标准化基线,促进有意义的方法验证,
3)衡量数据集适用性的策略用于方法基准测试。
6. 如何使用
作者提供三个新预设,每个预设针对不同的 GPU VRAM 和计算预算:
- nnU-Net ResEnc M:与标准 UNet 配置类似的 GPU 预算。最适合具有 9-11GB VRAM 的 GPU。训练时间:A100 上约 12 小时
- nnU-Net ResEnc L:需要具有 24GB VRAM 的 GPU。训练时间:A100 上约 35 小时
- nnU-Net ResEnc XL:需要具有 40GB VRAM 的 GPU。训练时间:A100 上约 66 小时
作者推荐 nnU-Net ResEnc L 作为新的默认 nnU-Net 配置。
以下命令在((M/L/XL)中选择一个:
运行实验计划和预处理时指定所需的配置
1
nnUNetv2_plan_and_preprocess -d DATASET -pl nnUNetPlannerResEnc(M/L/XL)
运行
1
nnUNetv2_plan_experiment -d DATASET -pl nnUNetPlannerResEnc(M/L/XL)
新预设的训练结果将存储在专用文件夹中,并且不会覆盖标准 nnU-Net 结果。
扩展ResEnc nnU-Net
1
nnUNetv2_plan_experiment -d 3 -pl nnUNetPlannerResEncM -gpu_memory_target 80 -overwrite_plans_name nnUNetResEncUNetPlans_80G
运行上面的示例将产生警告(”You are running nnUNetPlannerM with a non-standard gpu_memory_target_in_gb”)。这里可以忽略这个警告。
当改动 VRAM 目标时,请务必使用 -overwrite_plans_name NEW_PLANS_NAME 更改计划标识符,以免覆盖预设计划。
扩展到多个 GPU 当扩展到多个 GPU 时,不要只向 nnUNetv2_plan_experiment 指定 VRAM 的组合量,因为这可能会导致 patch 大小太大而无法由单个 GPU 处理。最好让此命令针对一个 GPU 的 VRAM 预算运行,然后手动编辑计划文件以增加批处理大小。可以使用配置继承。在生成的计划 JSON 文件的配置字典中,添加以下条目:
"3d_fullres_bsXX": {
"inherits_from": "3d_fullres",
"batch_size": XX
},
其中 XX 是新的批量大小。如果 3d_fullres 对于一个 GPU 的 batch 大小为 2,并且计划扩展到 8 个 GPU,则将新的 batch 大小设置为 2x8=16.
然后,使用 nnU-Net 的多 GPU 设置来训练新配置:
1
nnUNetv2_train DATASETID 3d_fullres_bsXX FOLD -p nnUNetResEncUNetPlans_80G -num_gpus 8