论文笔记-Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
论文标题: Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation 论文地址:https://arxiv.org/pdf/2312.04265.pdf 代码:https://github.com/w1oves/Rein.git 发表于:CVPR 2024
作者起名的一些巧思:
- rein 缰绳
- harness 驾驭
- harness vision foundation model using rein
预训练视觉模型拥有强大的能力,为了利用预训练模型的泛化能力,作者提出针对领域泛化语义分割的微调方法,叫做 rein。
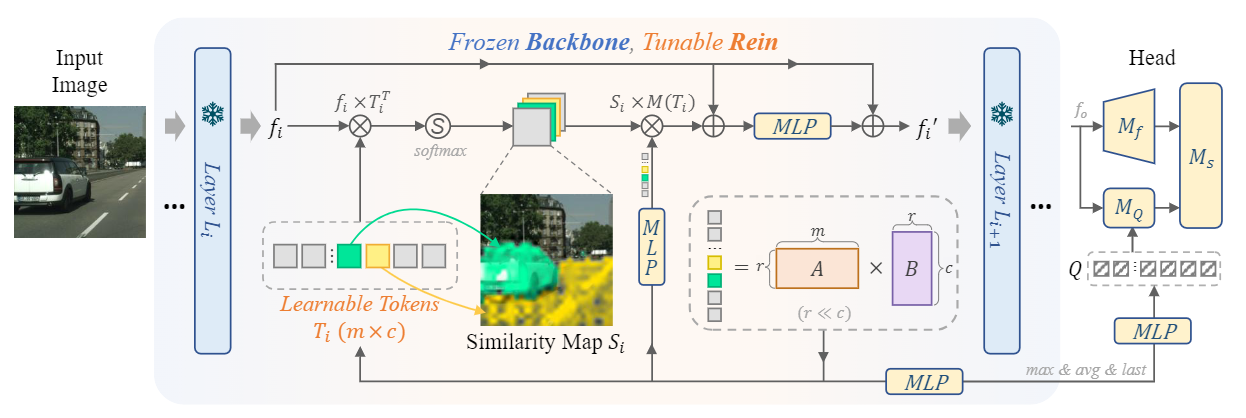
Rein-core
Rein 采用的思路是在每一层之间的特征上进行增强,即在原结构的 $L_i$ 层输出上加一个 $\Delta f_i$,这个 $\Delta f_i$ 应该帮助预训练视觉模型连接两个 gap,一个是预训练数据和目标场景之间的 gap,另一个是预训练任务和目标任务之间的 gap。
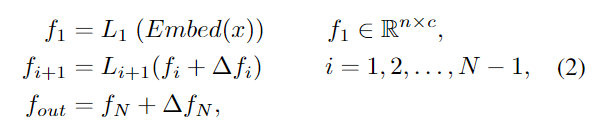
为了计算 $\Delta f_i$,作者利用了一个可学习的 tokens T,与原模型输出特征 $f_i$ 相乘,经过 softmax 之后得到相似性图,再与T相乘,过程类似于做 $f_i$ 和 $T$ 的 cross attention,然后加上原特征 $f_i$ 后经过一层 MLP,得到了 $\Delta \bar{f_i}$。下一层的输入是原特征加上 $\Delta \bar{f_i}$,得到 $\Delta f_i$,实现了对于原特征的增强。
Rein-link
除此之外作者也在 decoder head上做了改动,在 DERT-like 的目标检测结构中,使用了 object query 来查询是否有目标以及目标的位置,作者在这里采用了 mask2former head。作者将在 backbone 中计算的 T 加入了 object query Q 的计算。
具体来说就是对于每一层的 $T_i$ 经过一个 MLP 后得到每一层的 $Q_i$,用所有层的 Q 计算 $Q_max$,$Q_avg$ ,然后将 $Q, Q_max, Q_avg$ concat在一起,经过MLP,得到查询的 Q。
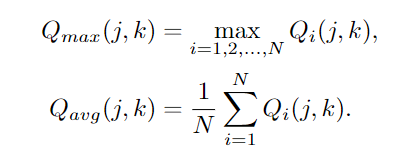
Rein-share & Rein-lora
在之前提到公式中,所有的 MLP 都是在层之间共享参数的,极大地减少了参数量。此外作者还利用了 Lora 分解T,$T_i=A_i \times B_i$,使得参数量进一步降低。 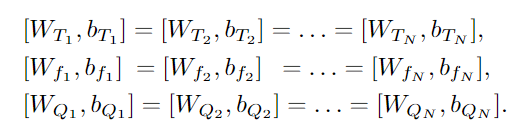
实验结果
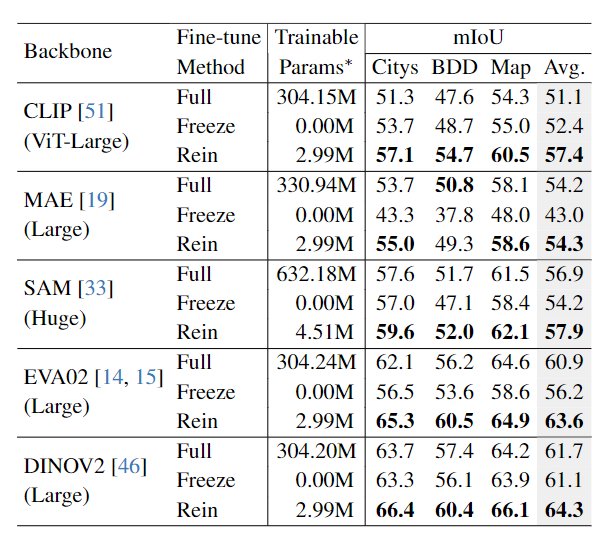
第一个表格对比了不微调、全参数微调和使用 rein 微调,实验是在 GTAV 数据集上微调,泛化到其他三个数据集上,结果表明作者提出的 rein 可以提高分割性能。
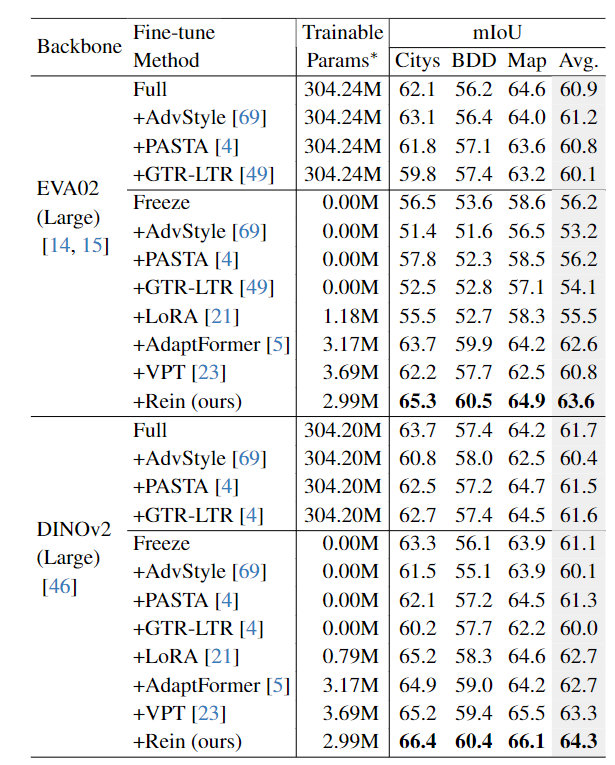
第二个表格是 rein 与其他微调方法的对比,表明 rein 不仅效果更好,参数量也相对较少。
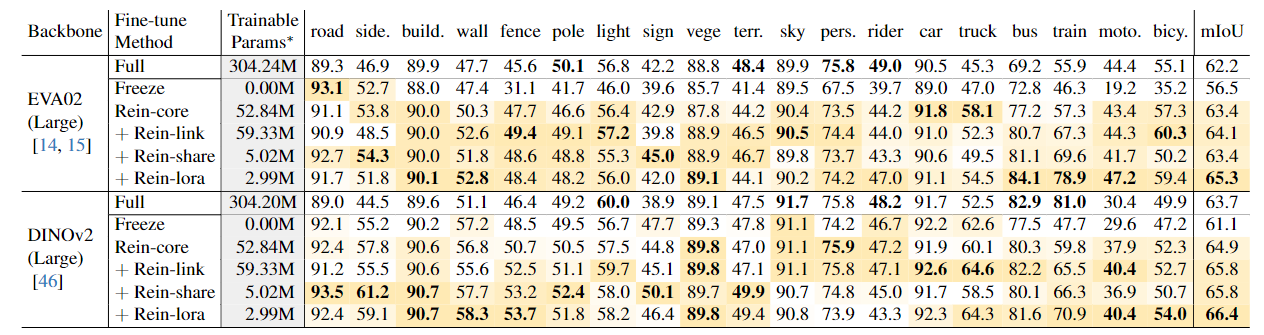
在消融实验里作者对比了各个部分的效果,在每一层上加 $\Delta f_i$ 的 rein-core 的平均表现就有了提高,加入Q 的微调后在一些物体的精度进一步提高, 而 share weight 的方法减少了参数量,同时保持了精度。Lora 的加入让参数量进一步减小,而平均表现有所提升。
与全参数微调方法相比, rein 不仅提高了精度,还减少了 GPU 显存的使用。
可视化结果
此外作者没有特意训练,但是夜间场景下取得了惊人的效果,也说明的模型的泛化能力。

总结
总结一下,作者为了利用预训练模型强大的泛化能力,提出了一种高效的微调方法,用很少的参数实现领域泛化语义分割上取得了优秀的表现。