利用Streamlit搭建带有RAG的聊天机器人
Chatbot 主要包括以下功能:
- 用户界面: 使用 Streamlit 构建交互界面。
- 模型加载: 支持加载本地 Hugging Face 模型或使用 API 的模型。
- RAG (检索增强生成)
- 使用 LlamaIndex 进行文档索引和检索。
- 支持上传 PDF 文件并将其添加到知识库。
- 根据用户问题和检索到的知识生成回答。
- 翻译: 使用 NLLB 模型进行翻译,用于处理双语检索。
一个经典的 RAG 流程如下,主要分为知识库数据准备和 RAG 两部分 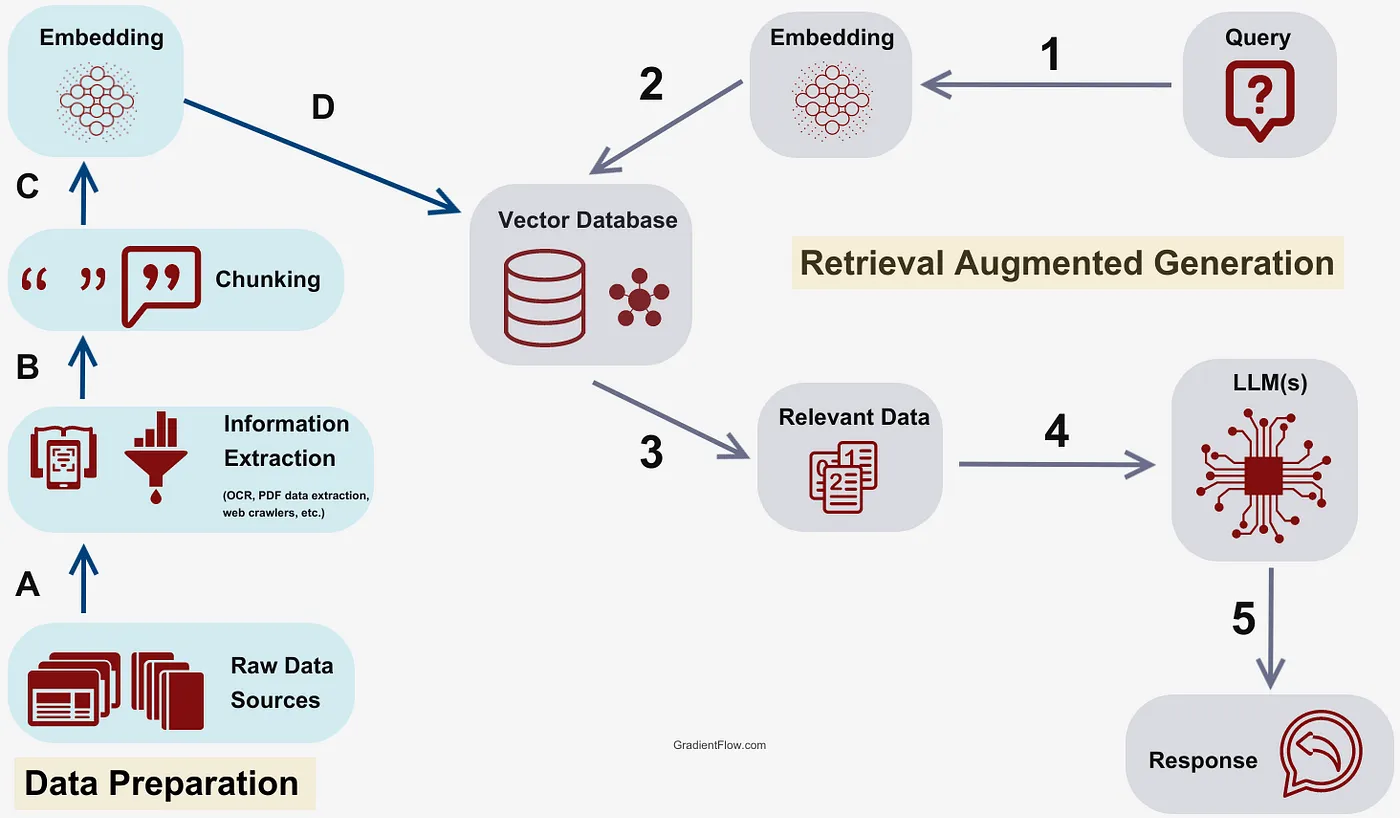
一、知识库构建
RAG 系统的知识库决定了能检索到什么信息,以及 LLM 最终能生成多好的回答。
A. 文档处理
目前先只考虑 PDF 和 Word 格式的文件,首先统一将它们转换为 Markdown 格式。
PDF 文档: 使用开源库 Marker 来处理 PDF,它能将复杂的 PDF 文档准确地转换为 Markdown 格式。PDF 中的图片会被单独存在一个文件夹里,现阶段只考虑使用语言模型,所以暂时忽略图片。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
import os
import json
from marker.config.parser import ConfigParser
from marker.models import create_model_dict
from marker.output import text_from_rendered, convert_if_not_rgb
from marker.settings import settings
from marker.converters.pdf import PdfConverter
def process_single_pdf(fpath, output_dir, force_ocr=False, use_llm=False):
config_parser = ConfigParser({
"output_format": "markdown",
"force_ocr": force_ocr,
"output_dir": output_dir,
"use_llm": use_llm,
"llm_service": "marker.services.openai.OpenAIService",
"openai_api_key": "your key",
"openai_model": "your model",
"openai_base_url":"your api",
"strip_existing_ocr": False
})
base_name = config_parser.get_base_filename(fpath)
config_dict = config_parser.generate_config_dict()
config_dict["disable_tqdm"] = True
model_dict = create_model_dict()
try:
converter = PdfConverter(
config=config_dict,
artifact_dict=model_dict,
processor_list=config_parser.get_processors(),
renderer=config_parser.get_renderer(),
llm_service=config_parser.get_llm_service()
)
rendered = converter(fpath)
text, ext, images = text_from_rendered(rendered)
text = text.encode(settings.OUTPUT_ENCODING, errors="replace").decode(
settings.OUTPUT_ENCODING
)
with open(
os.path.join(output_dir, f"{base_name}.{ext}"),
"w+",
encoding=settings.OUTPUT_ENCODING,
) as f:
f.write(text)
os.makedirs(os.path.join(output_dir, base_name), exist_ok=True)
with open(
os.path.join(output_dir, base_name, f"{base_name}_meta.json"),
"w+",
encoding=settings.OUTPUT_ENCODING,
) as f:
f.write(json.dumps(rendered.metadata, indent=2))
for img_name, img in images.items():
img = convert_if_not_rgb(img) # RGBA images can't save as JPG
img.save(os.path.join(output_dir, base_name, img_name), settings.OUTPUT_IMAGE_FORMAT)
print(f"Converted {fpath}")
del rendered
del converter
except Exception as e:
print(f"Error converting {fpath}: {e}")
Word 文档: 对于 Word 文档,使用 pypandoc 库将 .docx 或 .doc 文件转换为 Markdown 格式。
1
2
3
4
5
6
import pypandoc
def doc2md(doc_path):
file_save_path = str(pathlib.Path(doc_path).name) + '.md'
output = pypandoc.convert_file(
doc_path, 'md',
outputfile=file_save_path)
B. 分块与索引
一旦文档被标准化为 Markdown,我们就可以对其进行分块和索引。我们选择 LlamaIndex 作为文档索引框架。
LlamaIndex 能够将文档分割成更小的块(chunk),并为每个块创建向量表示。然后,这些向量被存储在向量数据库中。当用户提问时,LlamaIndex 会根据查询在这些向量中进行快速搜索,以找到最相关的文档块。
在使用 LlamaIndex 时不显式指定 NodeParser 或 TextSplitter,那么默认使用的分块器是 SentenceSplitter。
SentenceSplitter 是一种递归分块策略,它通过尝试使用一系列预定义的分隔符(如换行符、空格、标点符号等)来分割文本,并尽量在保持句子完整性的前提下,将块大小控制在目标范围内。
1
2
3
4
5
6
7
8
9
10
11
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
from llama_index.readers.file import MarkdownReader
# build index
documents = SimpleDirectoryReader(md_path).load_data()
index = VectorStoreIndex.from_documents(documents)
# 或者显式指定分块器
# text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=50)
# nodes = text_splitter.get_nodes_from_documents(documents)
# index = VectorStoreIndex(nodes=nodes)
C. 嵌入模型
嵌入模型的质量直接影响检索的准确性。
这里使用 BGE-M3 模型, BGE-M3 能够在多语言环境下工作,这对于处理来自不同语言的文档和查询至关重要。
1
2
3
4
5
6
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
myembed = HuggingFaceEmbedding(
model_name='.../BAAI/bge-m3')
Settings.embed_model = myembed
D. 保存向量数据库
保存 index 以便于下次直接调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# save index
index.storage_context.persist(persist_dir="./storage")
# load index
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
# update index
def update_database(new_files_names):
for new_file in new_files_names:
documents = MarkdownReader().load_data(os.path.join(md_path, new_file))
for doc in documents:
index.insert(doc)
print(new_file + " added to database.")
index.storage_context.persist(persist_dir=".storage")
二、问答系统
当用户输入一个问题时,整个系统的工作流如下:
- 用户提问: 用户输入一个问题。 将提问翻译为英语,分别计算嵌入,利用 BGE-M3 在多语言上的优势。翻译模型使用 NLLB,是一个轻量级模型,目的减轻计算压力。翻译成英文的目的是为了更好地检索英文文档。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
from langdetect import detect def load_translate_model(model_name="../ckpt/facebook/nllb-200-distilled-600M"): # 加载分词器 tokenizer = AutoTokenizer.from_pretrained(model_name) # 加载模型 model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(DEVICE) return model, tokenizer def translate_to_bilingual(text): # 检测输入语言 lang = detect(text) print(lang) if lang != 'zh-cn' and lang != 'zh-tw': # == 'en': # 如果输入是英文,翻译成中文 translation = translate_nllb(text, "eng_Latn", "zho_Hans") elif lang != 'en': # lang == 'zh-cn' or lang == 'zh-tw': translation = translate_nllb(text, "zho_Hans", "eng_Latn") else: translation = text return text, translation def translate_nllb(text, source_lang, target_lang): """ 使用 NLLB 模型进行翻译。 Args: text (str): 要翻译的文本。 source_lang (str): 源语言代码 (例如: "zh_CN" 代表中文, "en_US" 代表英文)。 target_lang (str): 目标语言代码 (例如: "en_US" 代表英文, "zh_CN" 代表中文)。 Returns: str: 翻译后的文本。 """ input_text = f"{source_lang} {text}" inputs = translate_tokenizer(input_text, return_tensors="pt").to(DEVICE) forced_bos_token_id = translate_tokenizer.convert_tokens_to_ids(target_lang) outputs = translate_model.generate( **inputs, forced_bos_token_id=forced_bos_token_id, max_length=512 ) translated_text = translate_tokenizer.decode(outputs[0], skip_special_tokens=True) return translated_text
- 双语检索: 同时使用用户的原始提问(例如中文)和翻译后的英文提问,分别计算嵌入并进行检索。这种双重检索策略可以最大化检索结果的召回率,尤其是在某些上下文中,翻译可能无法完全保留原始语义。
1 2 3 4 5 6 7 8 9 10
from llama_index.core.retrievers import VectorIndexRetriever retriever = VectorIndexRetriever( index=index, similarity_top_k=5 # Set the number of nodes to retrieve ) retrieved_nodes = [] # Perform a query for q in bilingual_promt: retrieved_nodes.extend(retriever.retrieve(q))
- 相关性排序: 将两次检索得到的所有结果进行统一的相关性排序,选择前k个作为最终检索结果。这里 k=5。
[0, 2, 4, 3, 1]的排序方式是因为在上下文比较长时, LLM会更加关注到头尾部分的内容,所以将权重高的检索结果放在头尾。1 2 3 4 5 6 7 8 9 10 11 12
combined = {} for node in retrieved_nodes: if node.node_id not in combined: combined[node.node_id] = {'score': node.score, 'node': node} else: combined[node.node_id]['score'] = max(node.score, combined[node.node_id]['score']) # 按 score 排序 ranked = sorted(combined.values(), key=lambda x: x['score'], reverse=True) source_nodes = [] for i in [0, 2, 4, 3, 1]: #range(5): source_nodes.append(ranked[i]['node'])
如果要用 reranker,只计算所有检索内容与原始query的分数(避免翻译有误),按照分数排序并取top n。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
def load_reranker_model(model_name="../ckpt/BAAI/bge-reranker-base"): tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side='left') model = AutoModelForSequenceClassification.from_pretrained(model_name).eval() return model, tokenizer # reranker def rerank_retrievals(queries, nodes, top_n=5): pairs = [[queries[0], node.text] for node in nodes] + [[queries[1], node.text] for node in nodes] # Tokenize the input texts inputs = reranker_tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512) scores = reranker_model(**inputs, return_dict=True).logits.view(-1, ).float() print(scores) scored_docs = sorted(zip(nodes, scores), key=lambda x: x[1], reverse=True) for node, score in scored_docs[:top_n]: print(f"score:{score}, text:{node.text}") # 返回排序后的前top_n个文档 topn = [node for node, score in scored_docs[:top_n]] source_nodes = [] for i in [0, 2, 4, 3, 1]: source_nodes.append(topn[i]) return source_nodes
- 输入 LLM: 根据预先定义的 prompt 模板,将用户的原始问题和检索到的文档块作为上下文,传递给本地或远程的 LLM。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
from transformers import AutoProcessor,AutoModelForCausalLM, AutoTokenizer, model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto") tokenizer = AutoTokenizer.from_pretrained(model_name) messages = [ { "role": "system", "content": "你是一个专业的AI助手,请根据知识库和上下文准确回答用户问题。" }, { "role": "user", "content": f"根据知识库:'{knowledge}', 根据上下文:'{chat_history}'," f"请回答:{prompt}", }, ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
- LLM 回答: LLM 基于这些上下文信息,生成最终的回答。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
def get_model_response_local(model, tokenizer, messages, do_sample=False, temperature=1.0, top_p=1.0, repetition_penalty=1.1): text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device) generated_ids = model.generate( **model_inputs, max_new_tokens=MAX_TOKENS, # 控制生成的 token 数量 do_sample=do_sample, # 启用采样, True, False temperature=temperature, # 控制生成的多样性, 0.7, 1.0 top_p=top_p, # nucleus sampling, 0.9, 1.0 repetition_penalty=repetition_penalty # 防止模型重复 ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] return response def get_model_response_api(model, messages, stream=True): response = client.chat.completions.create( # model='Pro/deepseek-ai/DeepSeek-R1', model=model, messages=messages, stream=stream ) return response
三、利用 Streamlit 实现界面
选择模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import streamlit as st st.title("Chatbot") option = st.selectbox( "请选择模型", ( "api:deepseek-ai/DeepSeek-R1-Distill-Qwen-7B", "local:Qwen/Qwen2.5-7B-Instruct-GPTQ-Int8", ), index=0, ) st.write("正在使用模型:", option)
- 加载模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor,AutoModelForCausalLM, AutoTokenizer, AutoModelForSeq2SeqLM @st.cache_resource def load_model(model_name): model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto") tokenizer = AutoTokenizer.from_pretrained(model_name) return model, tokenizer if LOCAL_MODEL: model, tokenizer = load_model(model_name) client = None else: api_key = st.secrets.get("openai_api_key") client = OpenAI(api_key=api_key, base_url="") model = tokenizer = None
- 加载翻译模型
1 2 3 4 5 6 7 8 9
@st.cache_resource def load_translate_model(model_name="./ckpt/facebook/nllb-200-distilled-600M"): # 加载分词器 tokenizer = AutoTokenizer.from_pretrained(model_name) # 加载模型 model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(DEVICE) return model, tokenizer
- 设置嵌入模型和其他相关,加载 index
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings, ServiceContext, StorageContext, load_index_from_storage from llama_index.embeddings.huggingface import HuggingFaceEmbedding from llama_index.core.llms import CustomLLM, CompletionResponse, CompletionResponseGen, LLMMetadata from llama_index.core.callbacks import CallbackManager from llama_index.core.indices.prompt_helper import PromptHelper from llama_index.core.llms.callbacks import llm_completion_callback from llama_index.readers.file import MarkdownReader from llama_index.core.retrievers import VectorIndexRetriever myembed = HuggingFaceEmbedding( model_name='./ckpt/BAAI/bge-m3', ) prompt_helper = PromptHelper( context_window=8191, # 必须和 metadata 一致 num_output=MAX_TOKENS, chunk_overlap_ratio=0.1, ) Settings.llm = None Settings.embed_model = myembed Settings.prompt_helper = prompt_helper print("load index") storage_context = StorageContext.from_defaults(persist_dir="../LLMProject/storage") index = load_index_from_storage(storage_context)
到此为止模型相关的初始化就完成了,接下来是聊天部分的实现。
- 记录和显示聊天记录
1 2 3 4 5 6 7 8
# Initialize chat history if "messages" not in st.session_state: st.session_state.messages = [] # Display chat messages from history on app rerun for message in st.session_state.messages: with st.chat_message(message["role"]): st.markdown(message["content"])
- 用户输入聊天内容,获取响应并返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69
# 用户输入 if prompt := st.chat_input( "Say something and/or attach a file", accept_file=True, file_type=["pdf"], ): explain = None input_text = prompt.text # collect history chat_history = "" for round in st.session_state.messages: round_message = "" round_message += round['role'] + ":" + round['content'] chat_history += round_message + "\n" with st.chat_message("user"): st.markdown(prompt.text) st.session_state.messages.append({"role": "user", "content": input_text}) if prompt["files"]: filename = prompt["files"][0].name.replace('pdf', 'md') if filename.endswith("pdf"): # add to database file_save_path = f"./test_database/{filename}" if not pathlib.Path.exists(pathlib.Path(file_save_path)): with open("uploaded_file.pdf", "wb") as f: f.write(prompt["files"][0].getbuffer()) process_single_pdf(fpath="uploaded_file.pdf", output_dir="./test_database") # update database documents = MarkdownReader().load_data(file_save_path) for doc in documents: index.insert(doc) index.storage_context.persist(persist_dir="./storage") storage_context = StorageContext.from_defaults(persist_dir="./storage") index = load_index_from_storage(storage_context) print(file_save_path + " successfully added to database.") if prompt.text.isspace() or prompt.text == "": if explain is not None: bot_response = explain else: bot_response = "No message given." else: bot_response, retrieve_response, source_files = get_response(model, tokenizer, index, input_text, chat_history) # Display assistant response in chat message container with st.chat_message("assistant"): if LOCAL_MODEL: st.markdown(bot_response) else: bot_response = st.write_stream(bot_response) try: with st.sidebar: st.markdown(source_files) st.title("检索结果") for text in retrieve_response.split(";;"): st.markdown(text) except: pass # Add assistant response to chat history st.session_state.messages.append({"role": "assistant", "content": bot_response})
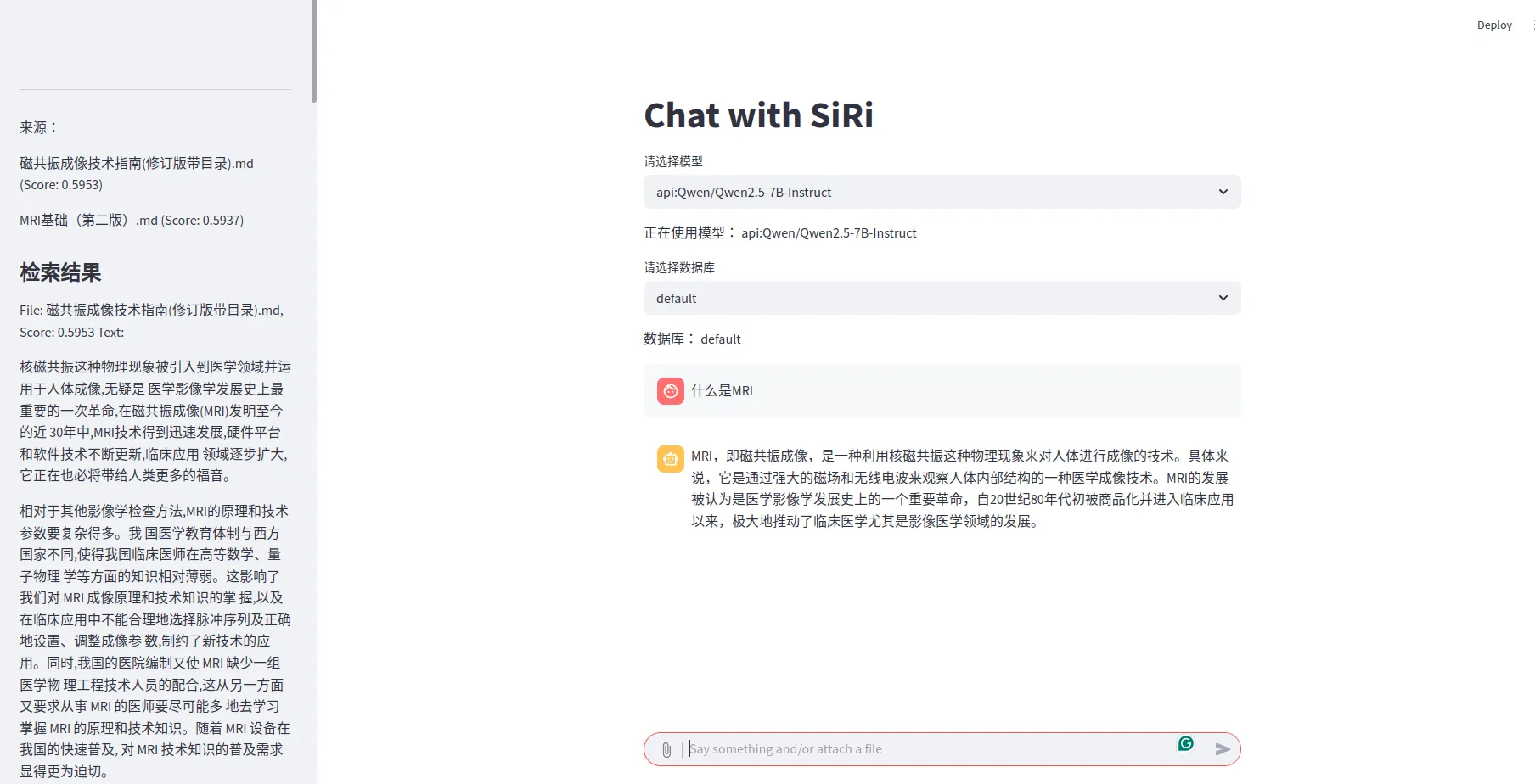
最终效果图