Sora 技术报告笔记
报告地址:https://openai.com/research/video-generation-models-as-world-simulators
技术报告主要介绍了两个方面:
(1)将所有类型的视觉数据转化为统一表示的方法,从而能够大规模训练生成模型;
(2)对Sora的能力和局限性的定性评价。
这里我们主要关注(可能用到的)技术部分。
将视觉数据转化为 patches
LLM 成功的关键之一是使用了 token 统一了文本代码、数学和各种形式的不同模态。为了继承这一优势, Sora 使用了视觉 patches。Patch 之前已被证明是视觉数据模型的有效表示(15,16,17,18)。作者发现,对于在各种类型的视频和图像上训练生成模型来说,patch 是一种可扩展性强且有效的表示方法。
15 Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
16 Arnab, Anurag, et al. “Vivit: A video vision transformer.” Proceedings of the IEEE/CVF international conference on computer vision. 2021.
17 He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022
18 Dehghani, Mostafa, et al. “Patch n’Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.” arXiv preprint arXiv:2307.06304 (2023)
这一部分引用的 4 篇文章, ViT、Vivit、MAE、Patch n’ Pack,都是在视觉领域大获成功的方法,应该只是介绍一下。
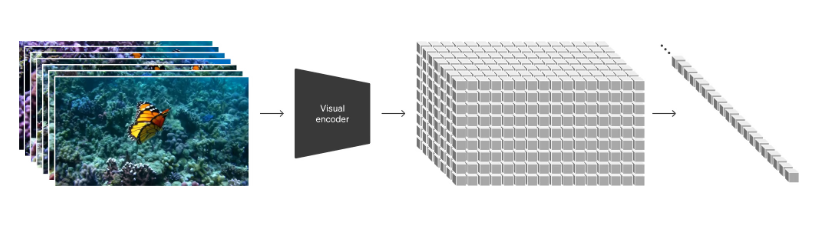
在较高层面上,作者首先将视频压缩到较低维的潜在空间(19), 然后将表示分解为时空 patches,从而将视频转换为 patch。
19 Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
这里引用了 LDM 的论文, LDM 先训练一个 autoencoder 将图像压缩到一个低维潜在空间上,这个空间直觉上和图像空间是等效的,但是减少了很多计算量。
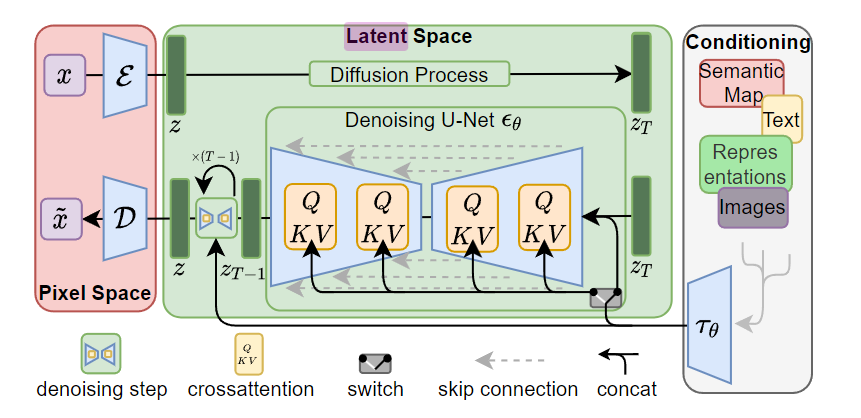
给定 RGB 空间中的图像 $x ∈ \mathbb{R}^{H×W ×3}$,编码器 $\mathcal{E}$ 将 $x$ 编码为潜在表示 $z=\mathcal{E} (x)$ ,而解码器 $\mathcal{D}$ 从潜在表示中重建图像,$\tilde{x} = \mathcal{D}(z) = \mathcal{D}(\mathcal{E}(x))$,其中 $z ∈ \mathbb{R}^{h×w×c}$。重要的是,编码器按因子 $f = H/h = W/w$ 对图像进行下采样,作者研究了不同的下采样因子 $f = 2^m$,其中 $m ∈ N$。
通过训练的由 $\mathcal{E}$ 和 $\mathcal{D}$ 组成的感知压缩模型,可以得到一个有效的、低维的潜在空间,其中高频、不可察觉的细节被抽象出来。与高维像素空间相比,该空间更适合基于似然的生成模型,因为它们现在可以(i)专注于数据的重要语义位,以及(ii)在一个低维度、计算更高效的空间中进行训练。
视频压缩网络
作者训练了一个降低视觉数据维度的网络(20)。 该网络将原始视频作为输入,并输出在时间和空间上压缩的潜在表示。 Sora 在这个压缩的潜在空间中接受训练并随后生成视频。作者还训练了相应的解码器模型,将生成的潜伏映射回像素空间。
20 Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013)
压缩模型引用的是 VAE,结合 LDM 的结构来看,$\mathcal{E}$ 和 $\mathcal{D}$ 应该就是 VAE 的编码器和解码器。
时空 patch
给定一个压缩的输入视频,提取一系列时空 patch 作为 transformer tokens。该方案也适用于图像,因为图像只是具有单帧的视频。 基于 patch 的表示使 Sora 能够对不同分辨率、持续时间和长宽比的视频和图像进行训练。在推理时,可以通过在适当大小的网格中排列随机初始化的 patch 来控制生成视频的大小。
结合上面的图片来,这里的时空应该指的是 patch 在时间上和空间上都有采样。假设输入视频 $x ∈ \mathbb{R}^{N×H×W×3}$,编码器 $\mathcal{E}$ 将 $x$ 编码为潜在表示 $z=\mathcal{E} (x)$,其中 $z ∈ \mathbb{R}^{n×h×w×c}$,N 是视频的帧数, H 和 W 是图像尺寸。然后将 $z$ 变成一列输入 token,加入位置编码等等。
用于视频生成的缩放变压器
Sora 是扩散模型;给定输入噪声 patch(以及文本提示等调节信息),它被训练来预测原始的“干净” patch。重要的是,Sora 是一个diffusion transformer(26)。
26 Peebles, William, and Saining Xie. “Scalable diffusion models with transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023
生成模型主干是 DiT。
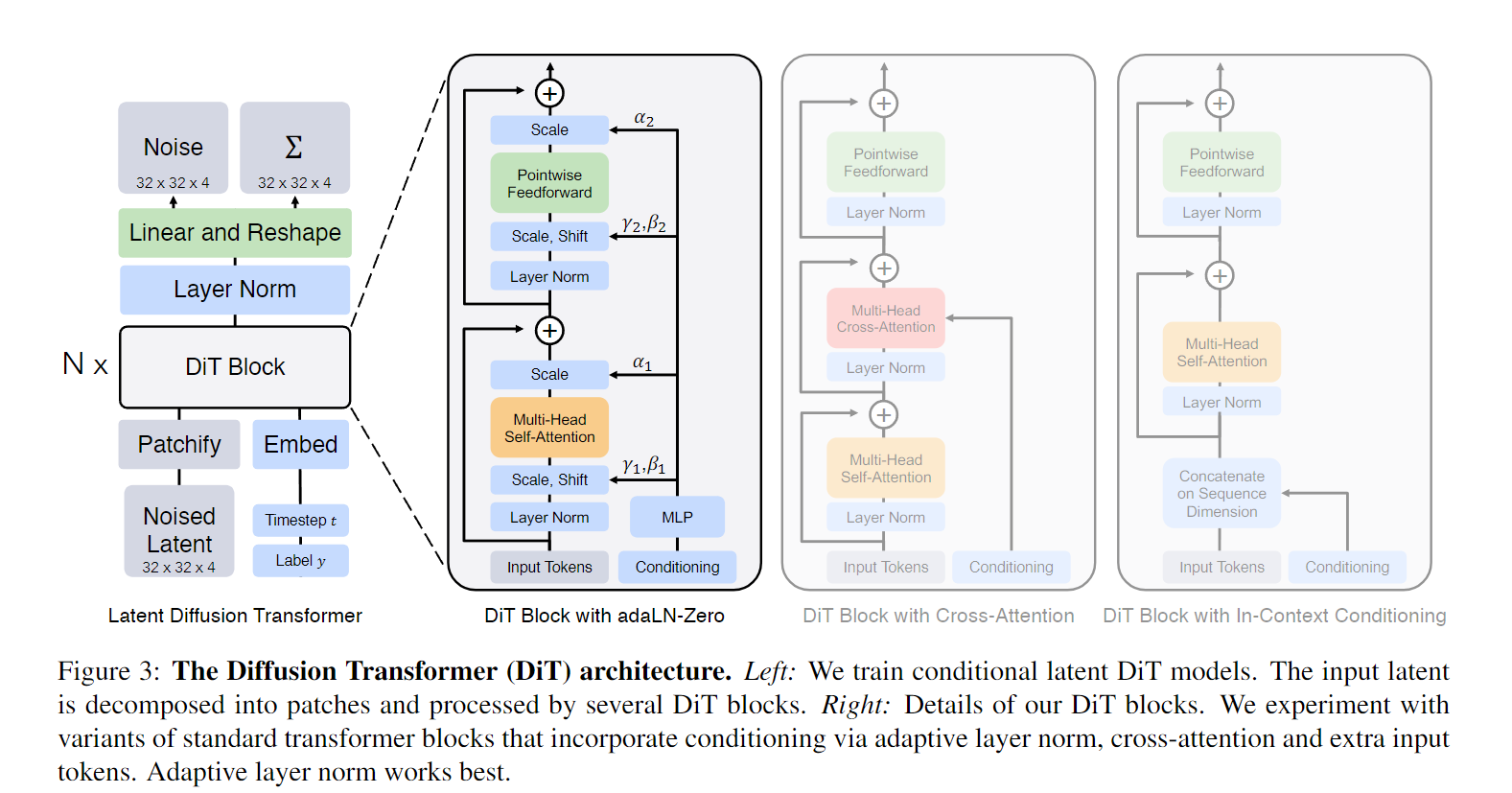
至此 Sora 所用到的结构大致就清楚了, 先在原始视频数据上训练一个 VAE 模型,用于学习潜在空间。用训练好的 VAE 编码器将视频压缩到低维潜在空间的特征表示,对表示划分 patch得到 token,拿去训练 DiT。
这么一看 Sora 似乎没有什么创新点(手动狗头),至于为什么可以做到在长视频里保持一致性,或许和 GPT 一样都是大力出奇迹,或者(和)一些精巧的工程设计。