Transformer 和 Vision Transformer以及参数高效迁移学习(PETL)
1. Transformer
Transformer 结构首先是由 “Attention is all you need” 这篇文章提出来的,当时认为这个标题非常标题党,但是现在看来这个标题起的是非常正确的。 在Transformer结构提出之前,当时NLP任务的模型都不能捕获全局依赖关系。
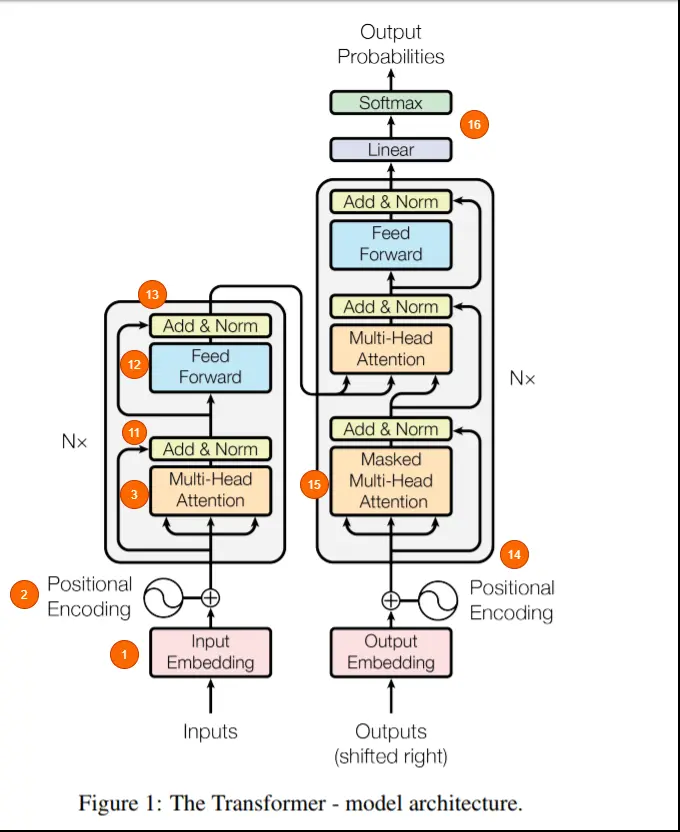 Transformer 结构
Transformer 结构
Transformer由两个结构组成,左边的encoder和右边的decoder。 Encoder的作用是把输入数据表示为一个中间的特征,而decoder的作用是把这个中间特征解码并输出。
下面的序号对应着上图中的编号。
1) 输入数据首先被嵌入到一个向量中,这个 embedding 层可以学习到每一个单词的特征向量。
2)位置编码被加入到 input embedding 中,这是因为如果不加入位置编码的话,就无法知道输入序列的顺序。
4)多头注意力包括三个可学习的向量:Query、Key、Value。这个 motivation 来自于,在进行查询的时候, 搜索引擎会将query和key比较,并且用value来响应。
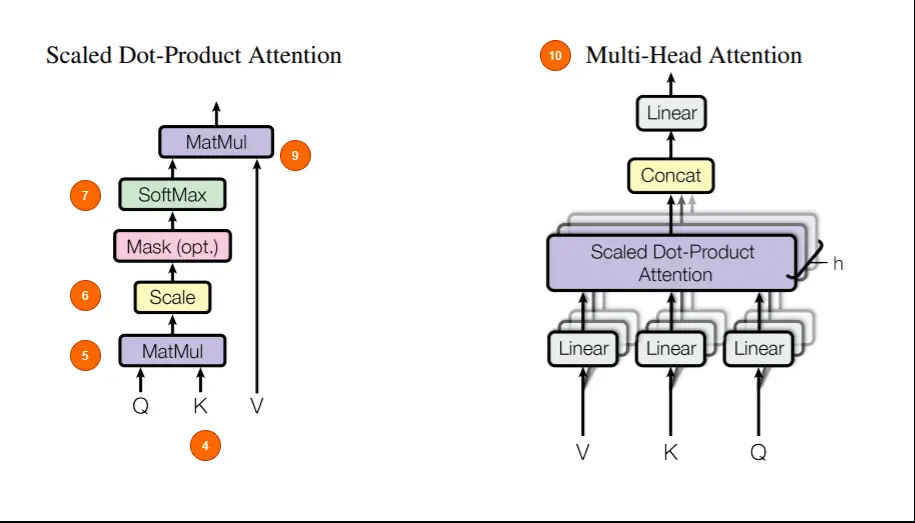
5)Q 和 K 特征经过点乘矩阵乘法得到一个分数矩阵,这个分数矩阵表示一个词关注其他单词的程度。分数更高意味着更多的关注。
6)根据 Q 和 K 向量的维度来缩小分数矩阵。这是为了保证稳定的梯度,因为乘法可能会产生梯度爆炸。
7)分数矩阵通过Softmax,被转化为概率,分数高的会被增强,低的分数会被抑制。这样做的目的是对为了确保模型对于哪些单词需要关注更加有信心。
8)将所得的概率的矩阵与V向量相乘,让模型学习到概率得分越高就越重要,概率得分低的单词是不重要。
9)Q、K 和 V 的向量级连,输出送到线性层进行进一步的处理。
10)自注意力是用在序列中的每一个单词上的。由于一个模块不依赖于另一个模块,因此可以使自注意力模块同时处理所有的东西,实现多头处理。
11) 输出向量与输入相加,实现残差连接,然后传入 LayerNorm 中进行归一化,LayerNorm有助于减少将训练时间,并稳定网络。
12) 输出被传递到 PositionwiseFeedForward 中,以获得更丰富的特征表示。
13) 输出与上一层输入进行残差相加,并进行 LayerNorm。
14) Encoder 的输出以及来自前一个时间步长或者前一个字的输入(如果有的话)被送到 Decoder 中。在 Decoder 中,前一时刻Decoder 的输出在经过 Masked multi-head attention,与 Encoder 的输出一起被送到下一个注意力模块 。
15) Masked multi-head attention的作用是,在 decode 时,网络不应该对序列中稍后出现的单词有任何可见性,以确保没有泄漏。这是通过在分数矩阵中屏蔽该系列后面的单词来实现的。序列中的当前单词和以前的单词加1,将来的单词得分加-inf。这确保了在执行 softmax 获得概率时,序列中的未来单词被淹没为0,而其余单词则被保留。
16) 输出送到线性层,并被softmax 以获得概率输出。
代码实现可以参考:Transformer代码及解析
2. Vision Transformer
在图像上使用 Transformer 的难点是, 图像是由像素组成的,如果按像素来计算会让计算量变得巨大。Google 提出了 ViT, 将图像划分为 patch 作为输入。ViT 的结构如下:
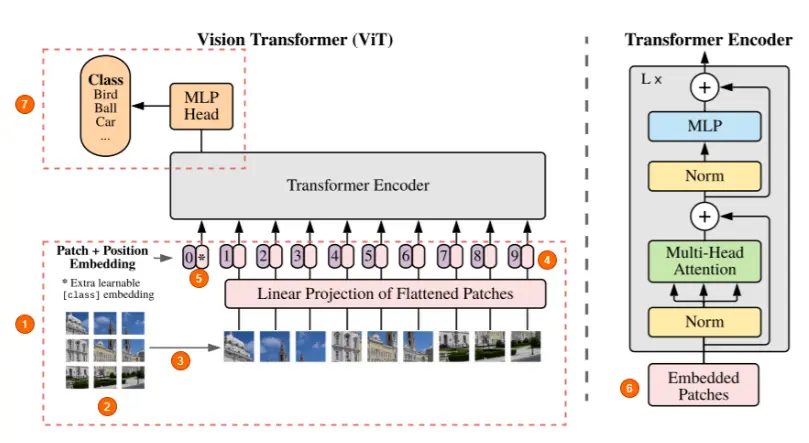
Patch Embedding
(1) 他们只使用 Transformer 的 encoder 部分。
(2) 图像被分成固定大小的 patch,尺寸可以是 16x16 或 32x32。Patch 越多也就意味着 patch size越小,网络训练就越容易。(所以这篇文章叫 An Image is Worth 16x16 Words)。
假设输入图像的大小为 $(height, width, channels)$, patch size为 $P$, 通道数为 $C$,图像会被分为 $N$ 个 大小为 $(P,P,C)$ 的 patch, $N=(height/P) \times (width/P)$。
(3) 将 patch 展平, 得到 $N$ 个大小为 $(1, P^2C)$ 的向量,并送到网络中进行进一步处理, 可以注意到这里图像是空间关系被打乱了。
(4) 模型不知道 patch 位置,因此,需要一个位置嵌入向量与图像一起输入 encoder。这里需要注意的一件事是, 位置嵌入也是可以学习的。
(5) 与 BERT 一样,开头(位置 0, 而不是末尾)也有一个特殊的 token,成为 CLS token。
(6) 每个图像块首先被展平成一个大向量,并与也是可学习的 embedding 矩阵相乘,得到 embedded patches。这些 embedded patches 与位置嵌入向量相结合,然后输入到 Transformer 中。
假设 embedding 的维度为 $D$, $N$ 个 $(1, P^2C)$ 的向量经过 embedding 得到 $N$ 个 $(1, D)$ 的向量,加上一个 CLS token,得到 $(N+1, D)$ 的向量。再加上一个大小相同的 $(N+1, D)$ 位置嵌入向量,得到后续网络的输入 $z_0$。
在论文中这一步被表达为公式:
\[z_0 = [x_{class};x_p^1E;x_p^2E;\cdots; x_p^NE]+E_{pos}, E\in \mathbb{R}^{(P^2 \cdot C)\times D}, E_{pos} \in \mathbb{R}^{(N+1) \times D}\]代码实现: 参考: https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class ViT(nn.Module):
def __init__(self, *):
super().__init__()
...
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
...
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
...
Transformer Encoder
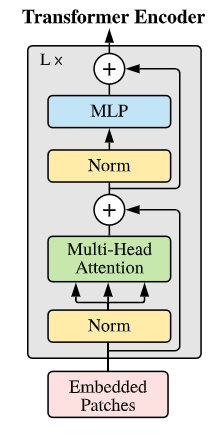
接下来的事情就是把 $z_0$ 传入 L 个 transformer encoders,对应于论文中的:
\[z'_l = MSA(LN(z_{l-1}))+z_{l-1}, \\z_l=MLP(LN(z'_l))+z'_l, \\ l=1 \dots L\]Encoder 包含多头注意力(MHA)机制和双层 MLP,中间有层归一化(LN)和残差连接。
LN 有助于稳定隐藏状态动态并减少训练时间,通过对每个训练实例的平均值和标准偏差进行缩放来实现的。得到的特征乘以缩放因子并添加到移位因子,两者都可以在训练期间学习。
残差连接为梯度提供替代路径,以解决非常深的架构中梯度消失的问题。
MLP 包含两层,采用 GELU 非线性设计,参数包括两个权重矩阵,大小分别为 $(D, D_{mlp})$ $(D_{mlp}, D)$。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class MLP(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
MHA 中,所有 $k$ 个头的结果会被 concatenate 合为最终的输出,通常每个头的维度为 $D_{h} = D/k$。在每个头中,可学习参数 Q,K,V 的大小均为 $D_h, D_h$。 QK 计算 attention,然后与 V 相乘,将 $k$ 个头的输出合在一起,得到 MHA 的 输出。公式如下:
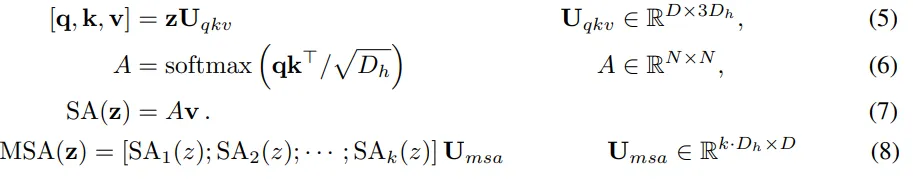
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class Attention(nn.Module):
def __init__(self, dim, num_head):
super(Attention, self).__init__()
self.num_head = num_head
head_dim = num_head // dim
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim*3)
self.attn_drop = nn.Dropout()
self.proj = nn.Linear(dim ,dim)
self.proj_drop = nn.Dropout()
def forward(self,x):
B,N,C = x.shape
qkv = self.qkv(x) # B,N,3C
qkv = qkv.reshape(B,N,3,self.num_head, C//self.num_head).permute(2,0,3,1,4)
q,k,v = qkv[0], qkv[1], qkv[2] # B,H,N,c
attn = (q @ k.transpose(-2,-1)) * self.scale # B,H,N,N
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1,2).reshape(B,N,C) # B,H,N,c -> B,N,H,c -> B,N,C
x = self.proj(x)
x = self.proj_drop(x)
return x,attn
Classification Head
(7) 唯一的区别是, encoder 的输出直接传递到前馈神经网络以获得分类输出, 没有使用 decoder。
输出为 $y = MLP(LN(z_l^0))$, 参数为 MLP 的权重矩阵 $(D, N_cls)$
计算参数
假设有 $P=16, D=768, L=12, k=12, MLP_hidden=3072$(ViT-base的配置),根据上面的介绍可以计算出模型的参数量:
Patch embedding + Position embeding \(P²*C*D + (N+1)*D = 256*3*768 + 257*768 = 787200\)
L 个 block, 每个里面计算 k 个头的 QKV+ Q*K+ 2个MLP($D$ 而不是 $D_h$,把 k乘进去了 ) \(L*(k*D*3*Dₕ + D*D + D*Dₘₗₚ + Dₘₗₚ*D) \\ = 12*(12*768*3*64 + 768*768 + 2*768*3072) = 84934656\)
假设在 ImageNet 上预训练,有1000类,最后的分类 MLP 参数 $768 * 1000 = 768000$
上数之和为 86489856, 大约86M.
3. ViT 的发展
ViT 有一些列不同大小的模型:
| 模型 | depth | width | heads | patch size | 预训练数据集 | 参数量 |
|---|---|---|---|---|---|---|
| ViT-Tiny/16 | 12 | 192 | 3 | 16 $\times$ 16 | ImageNet-21k | 5.7M |
| ViT-Small/16 | 12 | 384 | 6 | 16 $\times$ 16 | ImageNet-21k | 22.1M |
| ViT-Base/16 | 12 | 768 | 12 | 16 $\times$ 16 | ImageNet-21k | 86.4M |
| ViT-Large/16 | 24 | 1024 | 16 | 16 $\times$ 16 | ImageNet-21k | 304.4M |
| ViT-Huge/16 | 32 | 1280 | 16 | 16 $\times$ 16 | ImageNet-21k + JFT-300M | 632.2M |
| ViT-Giant/14 | 40 | 1408 | 16 | 14 $\times$ 14 | ImageNet-21k + JFT-300M | ~1.3B |
| ViT-B/32 | 12 | 768 | 12 | 32 $\times$ 32 | ImageNet-21k + JFT-300M | ~86.4M |
| DeiT-Tiny/16 | 12 | 192 | 3 | 16 $\times$ 16 | ImageNet-1k + distillation + augmentation | ~5.7M |
| DeiT-Small/16 | 12 | 384 | 6 | 16 $\times$ 16 | ImageNet-1k + distillation + augmentation | ~22.1M |
继最初的Vision Transformer之后,又有一些后续的工作:
- DeiT,针对ViT数据需求量高的问题吗,DeiT 引入了蒸馏方法,提出了 distillation token,并且发现使用卷积作为教师网络能取得更好的效果。 DeiT 有 4 种变体可用(3 种不同尺寸):facebook/deit-tiny-patch16-224、facebook/deit-small-patch16-224、facebook/deit-base-patch16-224 和 facebook/deit-base-patch16- 384。
- Swin Transformer, 引入了类似于 CNN 的滑窗和层级结构,引入了局部性,也减少了计算量。
- BEiT, BEiT 模型使用受 BERT启发并基于 VQ-VAE 的自监督方法,性能优于有监督的预训练 vision transformers。
- DINO,是一种自监督训练方法。使用 DINO 方法训练的视觉 Transformer 显示出卷积模型所没有的非常有趣的特性,无需接受过训练能够实现分割。
- MAE,通过预训练 Vision Transformer 来重建大部分 (75%) masked patches 的像素值(使用非对称编码器-解码器架构),作者表明,这种简单的方法在微调后优于有监督的预训练。
4. ViT 的 迁移学习
ViT 是目前视觉预训练模型的主要结构,随着预训练模型的规模不断扩大,在下游任务数据集上进行微调很可能会过拟合,而且训练或微调一个大模型成本很高。为此,我们需要参数高效迁移学习(Parameter-Efficient Transfer Learning, PETL),其目的是通过修改尽可能少的参数,使大规模预训练模型适应各种下游任务。目前提出的方法大致可以分为以下几种:
Adapter
Adapter 的结构通常为两层全连接层组成的 bottleneck block, 一层做 down scale,一层做 up scale, \(W_{down} ∈ \mathbb{R}_{d×h} , W_{up} ∈ \mathbb{R}^{h×d}, h << d.\) 加入adapter 的方式有两种,一种是顺序插入,也就是把原本的特征与经过 adapter 的特征相加,获得新的特征。 \(X' \leftarrow X +\phi(XW_{down})W_{up}\)
另一种是平行加入,在原本的结构上加一条额外的分支,形成residual connection,目的是让改变后的结构可以做的保留原来的特征。
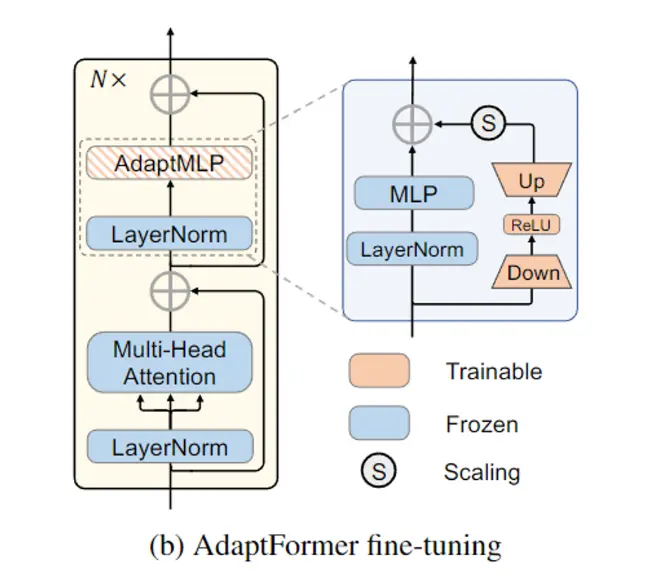
优点是仅需训练 adapter 模块的少量参数,训练代价小,可移植性强,可以避免对之前参数的遗忘。 缺点是会增加模型推理时间。
LoRA
LoRA 将 query 和 value 的增量分解为低秩矩阵,即 $\Delta W=AB$, \(A_{q/v} ∈ \mathbb{R}^{d×r}, B_{q/v} ∈ \mathbb{R}^{r×d},r << d.\) 然后 Q 和 V 被计算为 \(Q/V \leftarrow XW_{q/v}+s \cdot XA_{q/v}B_{q/v}\)
优点是推理阶段不会引入额外的参数,容易训练,缺点是在生成任务上可能效果欠佳。
Prompt
VPT 将可训练的参数加入encoder 的输入 embedding 中
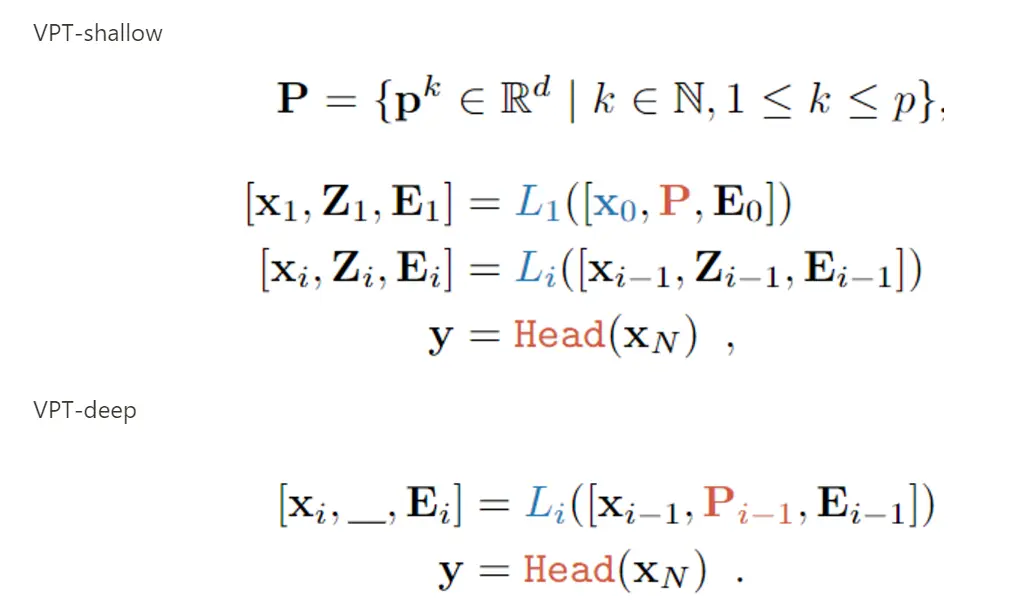
在下游任务训练过程中,仅更新提示和线性头的参数,而整个 Transformer 编码器被冻结。也可以在像素级别上加入 prompt, 但是实验证明效果不如在 latent space加。
优点是可以保证预训练模型结构和参数不变,比较灵活。 缺点是难以训练, prompt 挤占了下游任务的输入空间
其他
其他一些简单的 fune-tune 方法,将预训练的主干网络视为特征提取器,其权重在调整过程中是固定的,只关注分类头:
- 线性:仅使用线性层作为分类头。
- Partial-k:微调骨干网的最后 k 层,同时冻结其他层,重新定义了主干和分类头的边界。
- Mlp-k:利用具有 k 层的多层感知器(MLP)而不是线性层作为分类头。